Revolutionising Language Learning: How AI and Oracle APEX Transform Everyday Challenges

I'm finally finding more time, post-conference, to catch up on my writing. In this latest post, I'd like to talk about a presentation that I did at Kscope23, "Solving Everyday Problems with the Oracle Cloud". During the session, I had described and demonstrated how we can use the Oracle Cloud Infrastructure (OCI) AI services and Oracle APEX to build compelling solutions, even for personal life challenges.
Background
We are constantly bombarded by news about Artificial Intelligence (AI) and Machine Learning (ML), driving many of us seek to find a strong use case to take advantage of these technologies and use them in our work and personal projects. I am no exception.
A few years ago, I started learning the Japanese language using Duolingo, but had a lot of trouble remembering the Hiragana, Katakana, Kanji characters, same issues when I learned Mandarin in school. Back in the days, learning Mandarin was through rote learning, and that sometimes involved flashcards. In August 2021, I published an article through the Oracle Developer Relations team, about how I had used a M5Stack IoT device and some OCI resources to build a self-updating electronic flashcard that I could place on the refrigerator door. However, constantly updating the content repository can be tedious.
Less than a year later, two developments at Oracle made it easier for me to enhance the data entry process with AI-based technologies, specifically, Natural Language Processing (NLP). First, the Speech service was released on Feb 23, 2022. Later, in October 2022, a second version of the Language service was released with a new feature for performing language translation tasks. Both these added features from Oracle AI provided me an opportunity to "use AI" to improve my approach for entering new Japanese words into my online personal word bank.
I had blogged about this project previously, to celebrate the Joel Kallman Day last year. This follow-up article provides a technical deep dive to guide readers on how to implement as similar solution.
New AI-Enhanced Data Entry Workflow
"A picture speaks a thousand words", so here's are two workflow diagrams that provides a crude overview of how new words are entered today.
Speech-to-Text
As mentioned in my earlier post, when the speech service was first launched, it only supported the Waveform Audio File Format (WAV), and had strict rules on sample rates and channels. Today, the service now supports a much larger number of formats including FLAC, OGG, and WEBM. In the latest version of my application, only the MediaStream Recording API is used.
The audio capture and transcription job requests are performed through an Oracle APEX modal page shown below.
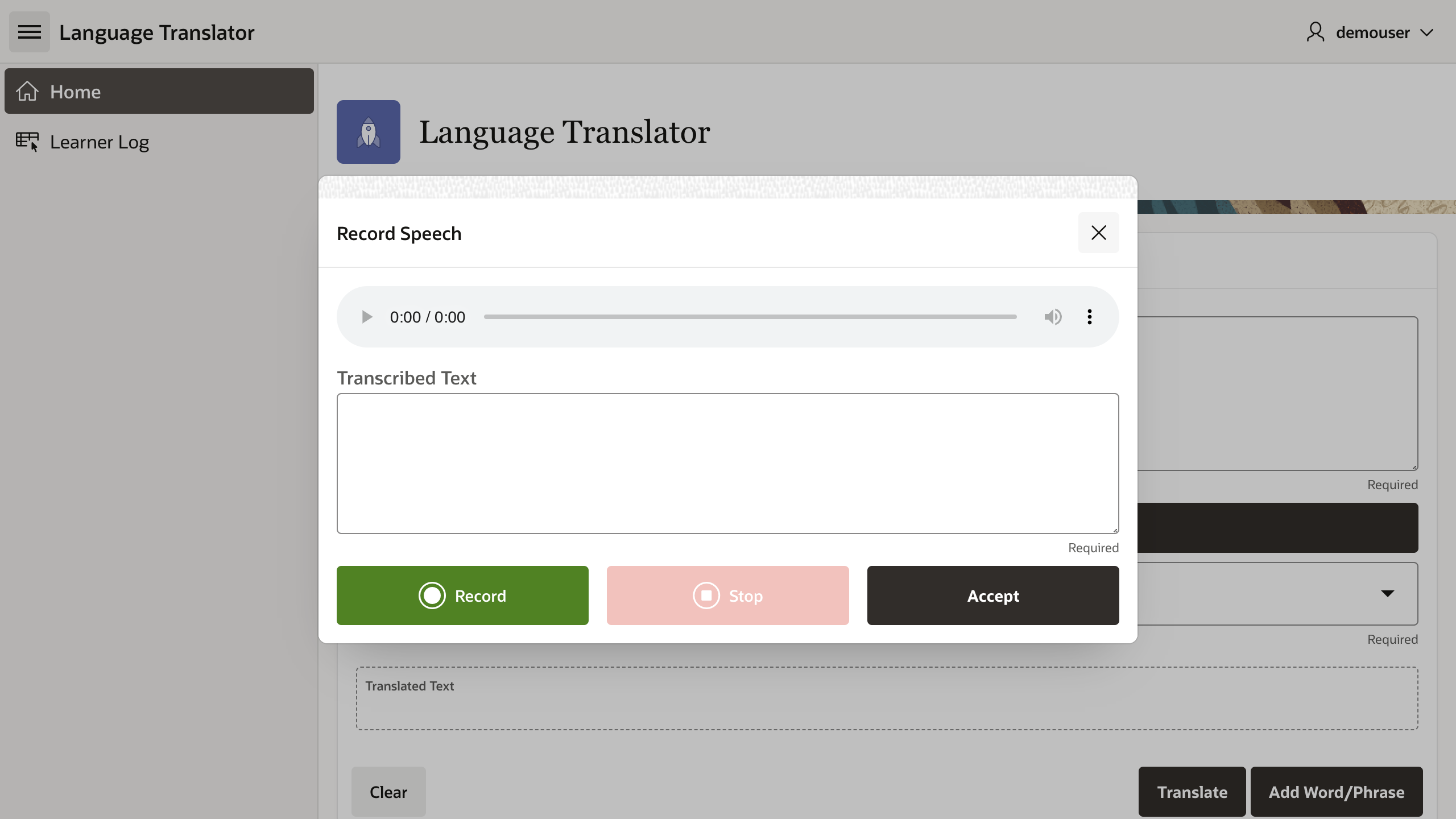
To start off, we will need some utility JavaScript functions, and for simplicity, I had declared this in the page's Function and Global Variable Declaration. Firstly, there's the mediaRecorder variable that stores the reference to the MediaRecorder object that we will instantiate at page load. It is followed by a simple utility functions that I had borrowed from Nick Buytaert. Reference to his blog post is in the comments.
let mediaRecorder;
const util = {
// builds a js array from long string
// credit: https://apexplained.wordpress.com/2016/09/12/chunked-multi-file-upload-with-ajax/
clob2Array: function (clob, size) {
let array = [];
loopCount = Math.floor(clob.length / size) + 1;
for (let i = 0; i < loopCount; i++) {
array.push(clob.slice(size * i, size * (i + 1)));
}
return array;
},
// converts blob to base64 string
blob2base64: function (blob) {
return new Promise(function(resolve, reject){
const fileReader = new FileReader();
fileReader.onerror = reject;
fileReader.onload = function() {
const dataURI = fileReader.result;
resolve(dataURI.substr(dataURI.indexOf(',') + 1));
}
fileReader.readAsDataURL(blob);
});
}
};
Next, I added the following JavaScript code in the Execute when Page Loads that would instantiate the MediaRecorder object, and implement the callback function when recording is stopped. When that function is called, the recorded audio will be loaded into an embedded audio player, allowing the user to playback the recording. It will also call an AJAX callback (TRANSCRIBE_AUDIO) process that includes the audio MIME-type, and the recording as a base64-encoded string. That's where the util package comes in handy.
if (navigator.mediaDevices) {
console.debug("getUserMedia supported.");
/**
* While FLAC is preferred, it appears Firefox and Chrome currently do not
* support this lossless audio format.
**/
let audioMimeType = 'audio/webm';
console.debug(audioMimeType + ' is' +
(MediaRecorder.isTypeSupported(audioMimeType) ? '' : ' not')
+ ' supported.');
const constraints = { audio: true };
let chunks = [];
navigator.mediaDevices
.getUserMedia(constraints)
.then((stream) => {
mediaRecorder = new MediaRecorder(stream);
mediaRecorder.onstop = async (e) => {
console.debug("data available after MediaRecorder.stop() called.");
var popup = apex.widget.waitPopup();
const blob = new Blob(chunks, { type: audioMimeType });
chunks = [];
const audioURL = URL.createObjectURL(blob);
player.src = audioURL;
console.debug("recorder stopped");
const base64 = await util.blob2base64(blob);
var process = apex.server.process(
"TRANSCRIBE_AUDIO",
{
x01: audioMimeType,
f01: util.clob2Array(base64, 32000)
}
);
process.done(function(result) {
apex.item("P2_TRANSCRIBED_TEXT").setValue(result.transcribedText);
apex.message.showPageSuccess("Audio transcribed.");
}).fail(function(jqXHR, textStatus, errorMessage) {
apex.message.alert("Failed to process audio.");
console.error("Failed to save. Error: " + errorMessage);
}).always(function() {
popup.remove();
});
};
mediaRecorder.ondataavailable = (e) => {
chunks.push(e.data);
};
})
.catch((err) => {
console.error(`The following error occurred: ${err}`);
});
}
The AJAX callback named TRANSCRIBE_AUDIO contains the following PL/SQL procedure:
declare
c_audio_mime_type constant apex_application.g_x01%type := apex_application.g_x01;
l_clob_temp clob;
l_blob_content blob;
l_buffer varchar2(32767);
l_filename varchar2(30) := 'sample-' || to_char(systimestamp, 'YYYYMMSSHH24MISS')
|| '.' || regexp_replace(c_audio_mime_type, '^audio/(.+)$', '\1');
l_transcribed_text varchar2(32767);
begin
dbms_lob.createtemporary(
lob_loc => l_clob_temp
, cache => false
, dur => dbms_lob.session
);
for i in 1..apex_application.g_f01.count loop
l_buffer := apex_application.g_f01(i);
dbms_lob.writeappend(
lob_loc => l_clob_temp
, amount => length(l_buffer)
, buffer => l_buffer
);
end loop;
l_blob_content := apex_web_service.clobbase642blob(l_clob_temp);
pkg_oci_os_util.p_upload_object(
p_bucket_name => :G_INPUT_BUCKET_NAME
, p_file_blob => l_blob_content
, p_filename => l_filename
, p_mime_type => c_audio_mime_type
);
dbms_lob.freetemporary(l_clob_temp);
l_transcribed_text := pkg_oci_speech_util.f_transcribe_audio(
p_input_bucket_name => :G_INPUT_BUCKET_NAME
, p_output_bucket_name => :G_OUTPUT_BUCKET_NAME
, p_filename => l_filename
);
sys.htp.p('{ "transcribedText": "' || l_transcribed_text || '"}');
end;
The callback process converts the base64-encoded string back to a BLOB, and then uploads it to the target Object Storage bucket defined by the APEX substitution string G_INPUT_BUCKET_NAME. Once the file has been uploaded successfully, the Speech service transcription job is then created using a facade. The PL/SQL function takes in the input and output bucket names, as well as the audio filename, and returns the transcribed text. The function also has an optional parameter p_source_language_code that lets the developer specify the language used in audio recording. The default value is en-US.
NOTE
If you have not worked with the Object Storage service in APEX before, be sure to check out the LiveLabs workshop I had prepared on this subject. I will also be presenting this workshop in-person at the upcoming Oracle CloudWorld 2023. The session number is HOL2327.
This function actually makes several OCI REST API calls. The first one creates the transcription job using standard APEX_WEB_SERVICE code shown in the snippet below:
apex_web_service.g_request_headers(1).name := 'Content-Type';
apex_web_service.g_request_headers(1).value := 'application/json';
l_response := apex_web_service.make_rest_request(
p_url => l_request_url
, p_http_method => 'POST'
, p_body => json_object(
key 'compartmentId' value pkg_oci_speech_util.gc_compartmentid
, key 'inputLocation' value json_object(
key 'locationType' value 'OBJECT_LIST_INLINE_INPUT_LOCATION'
, key 'objectLocations' value json_array(
json_object(
key 'bucketName' value p_input_bucket_name
, key 'namespaceName' value pkg_oci_speech_util.gc_namespace
, key 'objectNames' value json_array(p_filename)
)
)
)
, key 'outputLocation' value json_object(
key 'bucketName' value p_output_bucket_name
, key 'namespaceName' value pkg_oci_speech_util.gc_namespace
, key 'prefix' value 'apex'
)
, key 'normalization' value json_object(
key 'isPunctuationEnabled' value true
)
, key 'modelDetails' value json_object(
key 'languageCode' value p_source_language_code
)
)
, p_credential_static_id => pkg_oci_speech_util.gc_credential_static_id
);
The CreateTranscriptionJob API calls are asynchronous. When the job was created, the API returns a response object containing details about the transcription job, including the OCID, and the job's status (the id and lifecycleState attribute respectively). Rarely will the job complete immediately, therefore, the code then loops, making a call to the GetTranscriptionJob endpoint to get the current status until either job has succeeded, failed, or was cancelled.
If the transcription job was successful, the function then retrieves the task details using the GetTranscriptionTask API. The response will contain the required object storage location of the transcription results written in a JSON file (see example below).
{
"status": "SUCCESS",
"timeCreated": "2023-08-20 23:32:46.96",
"modelDetails": {
"domain": "GENERIC",
"languageCode": "en-US"
},
"audioFormatDetails": {
"format": "WEBM",
"numberOfChannels": 2,
"encoding": "OPUS",
"sampleRateInHz": 48000
},
"transcriptions": [
{
"transcription": "Hello, how are you?",
"confidence": "0.9600",
"tokens": [
{
"token": "This",
"startTime": "0.624s",
"endTime": "1.104s",
"confidence": "0.9527",
"type": "WORD"
},
...
]
}
]
}
In this file, you can find details about the source audio file, the transcription, the confidence value of the transcription, and details of individual tokens. The function retrieves this file from the object storage, parses it, and then returns the value of the transcription attribute.
Finally, this page contains the following UI components:
- An audio player to playback the recording. It can be embedded within a Static Content region using the source:
<audio id="player" controls style="width: 100%;"></audio> - A textarea page item called
P2_TRANSCRIBED_TEXT; and - Three buttons Record, Stop, and Accept.
The first two buttons trigger the media recorder object to start and stop recording. Simply attach dynamic actions for mouse click events and execute the corresponding JavaScript code.
// For the start button.
if(mediaRecorder) {
mediaRecorder.start();
}
// For the stop button.
if(mediaRecorder) {
mediaRecorder.stop();
}
The Accept button executes the Close Dialog process, returning the value of the page item P2_TRANSCRIBED_TEXT that is used to set the value of P1_TEXT in the parent page.
Translate Text
The Language service API is a lot simpler to consume. When the Translate button is clicked, the page is submitted, and a page submission process is called with to execute the following PL/SQL procedure:
declare
c_rest_url constant varchar2(200) := 'https://language.aiservice.us-phoenix-1.oci.oraclecloud.com/20221001/actions/batchLanguageTranslation';
c_from_lang constant varchar2(2) := 'en';
c_compartment_ocid varchar2(1024) := 'ocid1.compartment.oc1..*****';
c_credential_static_id constant varchar2(50) := 'OCI_CREDENTIALS';
c_number_of_text_to_translate pls_integer := 1;
l_request_body json_object_t;
l_document json_object_t;
l_documents json_array_t;
l_response clob;
begin
l_request_body := json_object_t();
l_documents := json_array_t();
/**
* The Language service APIs process requests in batches. Even though we are
* only submitting a single text to be translated, I have written a loop to
* construct the request body to "future proof" the implementation. ;-)
**/
for i in 1..c_number_of_text_to_translate
loop
l_document := json_object_t();
l_document.put('key', to_char(i));
l_document.put('text', :P1_TEXT);
l_document.put('languageCode', c_from_lang);
l_documents.append(l_document);
end loop;
l_request_body.put('documents', treat(l_documents as json_element_t));
l_request_body.put('targetLanguageCode', :P1_TO_LANG);
l_request_body.put('compartmentId', c_compartment_ocid);
apex_debug.info(l_request_body.to_string());
apex_web_service.g_request_headers(1).name := 'Content-Type';
apex_web_service.g_request_headers(1).value := 'application/json';
l_response := apex_web_service.make_rest_request(
p_url => c_rest_url
, p_http_method => 'POST'
, p_body => l_request_body.to_string()
, p_credential_static_id => c_credential_static_id
);
if apex_web_service.g_status_code != 200 then
apex_debug.error('HTTP Status Code: ' || apex_web_service.g_status_code);
apex_debug.error(l_response);
raise_application_error(-20002, 'Translation unsuccessful! HTTP Status Code: '
|| apex_web_service.g_status_code);
else
apex_debug.info(l_response);
l_documents := treat(json_object_t.parse(l_response).get('documents') as json_array_t);
for i in 0..(l_documents.get_size() - 1)
loop
l_document := treat(l_documents.get(0) as json_object_t);
:P1_TRANSLATED_TEXT := l_document.get_string('translatedText');
end loop;
end if;
end;
That's it!
Summary
In this article, we have delved into the remarkable synergy between AI and Oracle APEX. By harnessing cutting-edge AI features like speech-to-text transcription and language translation, we've unveiled a world of possibilities for enhancing communication and learning. Whether you're a beginner or an expert in the realm of machine learning, I hope this article has provided you a head start and inspiration for creating your own innovative solutions to solving day-to-day challenges using low-code technologies.