Get Started with Oracle Database 23ai AI Vector Search


While preparing for my upcoming Kscope24 presentations, I thought I'd introduce a section on Oracle's recently announced AI Vector Search that is now generally available with the Oracle Database 23ai rebranding and release. At the time of writing, you can either provision the new version of the database on the Oracle Cloud Infrastructure (OCI), download the Oracle Autonomous Database (ADB) Free container image, or the Oracle Database 23ai Free. On the OCI, you can either provision an Always Free ADB, or an Oracle Base Database service instance.
The documentation provided by Oracle is comprehensive and should get you started. Here, I condensed everything that I have learned so far into a step-by-step guide to get you started quickly.
Import a Pre-trained Model to Perform Embeddings
Prerequisites
OCI Tenancy
- A Compute instance.
- An Always Free ADB running the 23ai release.
- An Identity Access Management (IAM) Dynamic Group that includes the Compute instance.
- An IAM dynamic group that includes the ADB instance.
- An Object Storage bucket.
- A Policy that allows both dynamic groups to access the bucket and manage objects.
Oracle Autonomous Database
- Create an Oracle APEX workspace.
- As the ADB's admin user, execute the following script to ready your user.
-- Configure your user.
define myuser = 'wksp_somethingcreative';
-- Grant the resource principal privilege to the user.
exec dbms_cloud_admin.enable_resource_principal('&myuser.');
-- Additional grants.
grant create mining model to &myuser.;
grant execute on c##cloud$service.dbms_cloud to &myuser.;
grant execute on sys.dbms_vector to &myuser.;
grant execute on ctxsys.dbms_vector_chain to &myuser.;
grant read,write on directory data_pump_dir to &myuser.;
-- We don't need this for the tasks in this blog post, but the network ACL is
-- required when working with third-part APIs.
begin
dbms_network_acl_admin.append_host_ace(
host => '*'
, ace => xs$ace_type(
privilege_list => xs$name_list('connect')
, principal_name => '&myuser.'
, principal_type => xs_acl.ptype_db
)
);
end;
/
Install OML4py on Compute
- Download OML4Py 2.0 (Database 23ai) from here, and place the file in
/tmp. - Install the dependencies for the OML4Py client.
sudo dnf install -y perl-Env libffi-devel openssl openssl-devel tk-devel \
xz-devel zlib-devel bzip2-devel readline-devel libuuid-devel ncurses-devel \
gcc-c++ - And while you're at it 😉, install the OCI CLI.
sudo dnf -y install oraclelinux-developer-release-el8 python36-oci-cli - In case you haven't already noticed, I like to use Conda to manage my Python environments, so here are the steps1 for installing it on the Compute instance.
# Import our GPG public key
sudo rpm --import https://repo.anaconda.com/pkgs/misc/gpgkeys/anaconda.asc
# Add the Anaconda repository
cat <<EOF | sudo tee /etc/yum.repos.d/conda.repo
[conda]
name=Conda
baseurl=https://repo.anaconda.com/pkgs/misc/rpmrepo/conda
enabled=1
gpgcheck=1
gpgkey=https://repo.anaconda.com/pkgs/misc/gpgkeys/anaconda.asc
EOF
# Install Conda
sudo dnf install -y conda - Load Conda environment variables. Optionally, add this to the
opcuser's$HOME/.bashrc.. /opt/conda/etc/profile.d/conda.sh - Prepare the Conda environment file.
cat <<EOF | tee /home/opc/onnx-exporter.yaml
name: onnx-exporter
channels:
- defaults
dependencies:
- python=3.12
- pytorch-cpu=2.2.0
- pip
- pip:
- numpy>=1.26.0
- pandas==2.1.1
- SciPy>=1.12.0
- matplotlib==3.7.2
- setuptools==68.0.0
- oracledb>=2.0.0
- scikit-learn==1.3.2
- onnxruntime==1.17.0
- onnxruntime-extensions==0.10.1
- onnx==1.16.0
- transformers==4.38.1
- sentencepiece==0.2.0
EOF - Create the environment.
conda env create --file=onnx-exporter.yaml - Activate the environment.
conda activate onnx-exporter - Extract the OML4Py client files.
unzip /tmp/oml4py-client-linux-x86_64-2.0.zip -d installer && \
cd installer - Compile and deploy the client.
perl -Iclient client/client.pl -i -y - Set up the directory to export the ONNX files to.
EXPORT_PATH=/home/opc/model-exports
mkdir -p $EXPORT_PATH
cd $EXPORT_PATH - Set up more environment variables. Update the variables accordingly. As per the user guide, there are a few preconfigured models that can be deployed.
export OCI_CLI_AUTH=instance_principal
BUCKET_NAME=onnx-models
MODEL_NAME="sentence-transformers/all-MiniLM-L6-v2"
FILENAME=all-MiniLM-L6-v2 - Now export the model in ONNX.
cat <<EOF | python
from oml.utils import EmbeddingModel, EmbeddingModelConfig
em = EmbeddingModel(model_name="$MODEL_NAME")
em.export2file("$FILENAME", output_dir=".")
EOF - Then upload it to the object storage.
oci os object put -bn $BUCKET_NAME --file $FILENAME.onnx
Validate
- First, let's set some variables.
define tenancy_namespace = 'somethingrandom';
define region = 'us-phoenix-1';
define bucket_name = 'onnx-models'; - Then check that the ADB is able to access the objects in the bucket storing the ONNX models. If all goes well, you should see the ONNX file that you had uploaded.
select *
from dbms_cloud.list_objects(
credential_name => 'OCI$RESOURCE_PRINCIPAL'
, location_uri => 'https://&tenancy_namespace..objectstorage.®ion..oci.customer-oci.com/n/&tenancy_namespace./b/&bucket_name./o/'
);
Deploy the Pre-trained Model
- Download the ONNX file to an Oracle directory. For the always free ADB, you'll probably want to use the
DATA_PUMP_DIR.define onnx_filename = 'all-MiniLM-L6-v2.onnx';
define model_name = 'all_minilm_l6_v2';
begin
dbms_cloud.get_object(
credential_name => 'OCI$RESOURCE_PRINCIPAL'
, object_uri => 'https://&tenancy_namespace..objectstorage.®ion..oci.customer-oci.com/n/&tenancy_namespace./b/&bucket_name./o/&onnx_filename.'
, directory_name => 'DATA_PUMP_DIR'
, file_name => '&onnx_filename.'
);
end;
/ - Load the pre-trained model into the database.
begin
dbms_vector.load_onnx_model(
directory => 'DATA_PUMP_DIR'
, file_name => '&onnx_filename.'
, model_name => '&model_name.'
, metadata => json('{"function" : "embedding", "embeddingOutput" : "embedding" , "input": {"input": ["DATA"]}}')
);
end;
/ - Check that the model was loaded successfully.
select
model_name
, mining_function
, algorithm
, (model_size/1024/1024) as model_size_mb
from user_mining_models
order by model_name; - Finally, clean up and remove the ONNX file.
begin
dbms_cloud.delete_file(
directory_name => 'DATA_PUMP_DIR'
, file_name => '&onnx_filename.'
);
end;
/
Using the Pre-trained Model to Perform Embeddings
With my all-powerful embedding model, I can now "vectorize" some text using either the SQL function VECTOR_EMBEDDING, or the vector utility PL/SQL package DBMS_VECTOR. The simple SQL query below demonstrates both, and then calculates the euclidean and cosine distance between to show that vector outputs are basically identical.
define my_word = 'Cat';
with v as (
select
to_vector(vector_embedding(&model_name. using '&my_word.' as data)) as vector_using_function
, dbms_vector.utl_to_embedding(
data => '&my_word.'
, params => json(q'[{"provider": "database", "model": "&model_name."}]')
) as vector_using_utility_packages
)
select
v.vector_using_function
, v.vector_using_utility_packages
, v.vector_using_function <-> v.vector_using_utility_packages as euclidian_distance
, v.vector_using_function <=> v.vector_using_utility_packages as cosine_distance
from v;
A simple way for me to understand the power of this technology was to create an example. First, I created a table to store the name of the object, and then have a database trigger to perform and store the embeddings using the imported model.
create table my_dictionary(
id number generated always as identity
, word varchar2(100) not null
, description varchar2(500) not null
, word_vector vector not null
);
create or replace trigger my_dictionary_biu
before insert or update on my_dictionary
for each row
declare
begin
:new.word_vector := dbms_vector_chain.utl_to_embedding(
data => :new.word
, params => json(q'[{"provider": "database", "model": "&model_name."}]')
);
end;
/
Next, I created a vector index to, hopefully, make the search a little faster.
create vector index my_dictionary_ivf_idx
on my_dictionary(word_vector)
organization neighbor partitions
distance cosine
with target accuracy 95;
Then, insert some objects to query against.
insert into my_dictionary (word, description) values ('Cat', q'[A small animal with fur, four legs, a tail, and claws, usually kept as a pet or for catching mice.]');
insert into my_dictionary (word, description) values ('Car', q'[A road vehicle with an engine, four wheels, and seats for a small number of people.]');
insert into my_dictionary (word, description) values ('Dog', q'[A common animal with four legs, especially kept by people as a pet or to hunt or guard things.]');
insert into my_dictionary (word, description) values ('Bus', q'[A large vehicle in which people are driven from one place to another.]');
insert into my_dictionary (word, description) values ('House', q'[A building that people, usually one family, live in.]');
insert into my_dictionary (word, description) values ('Money', q'[Coins or notes (= special pieces of paper) that are used to buy things, or an amount of these that a person has.]');
insert into my_dictionary (word, description) values ('Fly', q'[1. (Verb) When a bird, insect, or aircraft flies, it moves through the air.
2. (Noun) A small insect with two wings.]');
insert into my_dictionary (word, description) values ('Bird', q'[A creature with feathers and wings, usually able to fly.]');
insert into my_dictionary (word, description) values ('Soap', q'[A substance used for washing the body or other things.]');
insert into my_dictionary (word, description) values ('Mosquito', q'[A small flying insect that bites people and animals and sucks their blood.]');
commit;
Now, suppose I wanted the database to return a list of three animals from the data set, the following SQL query will list the top 3 rows where the cosine distance between the search term and the object name is the smallest. This implies that they are semantically close to each other, compared to the remaining objects.
define search_term = 'Animals';
with subject as (
select to_vector(
vector_embedding(&model_name. using '&search_term.' as data)
) as search_vector
)
select
o.word
, o.word_vector <=> s.search_vector as cosine_distance
from my_dictionary o, subject s
order by cosine_distance(o.word_vector, s.search_vector)
fetch approx first 3 rows only with target accuracy 80;
A Quick APEX Application
Create a new application, and on page 1, create a textfield page item named P1_SEARCH_TERM, and a classic report. Add the following query as the source:
with subject as (
select to_vector(
vector_embedding(all_minilm_l6_v2 using :P1_SEARCH_TERM as data)
) as search_vector
)
select
d.word as search_title
, d.description as search_desc
, null as search_link
, 'Score' as label_01
, d.word_vector <=> s.search_vector as value_01
, null as label_02
, null as value_02
from my_dictionary d, subject s
where :P1_SEARCH_TERM is not null
order by cosine_distance(d.word_vector, s.search_vector)
fetch approx first 5 rows only with target accuracy 80
Set the classic report's template to Search Results, and add a dynamic action to refresh the report when P1_SEARCH_TERM is changed. When you enter a search term, you should get the top 5 words that are semantically similar in the results. For example, the word Kitten.
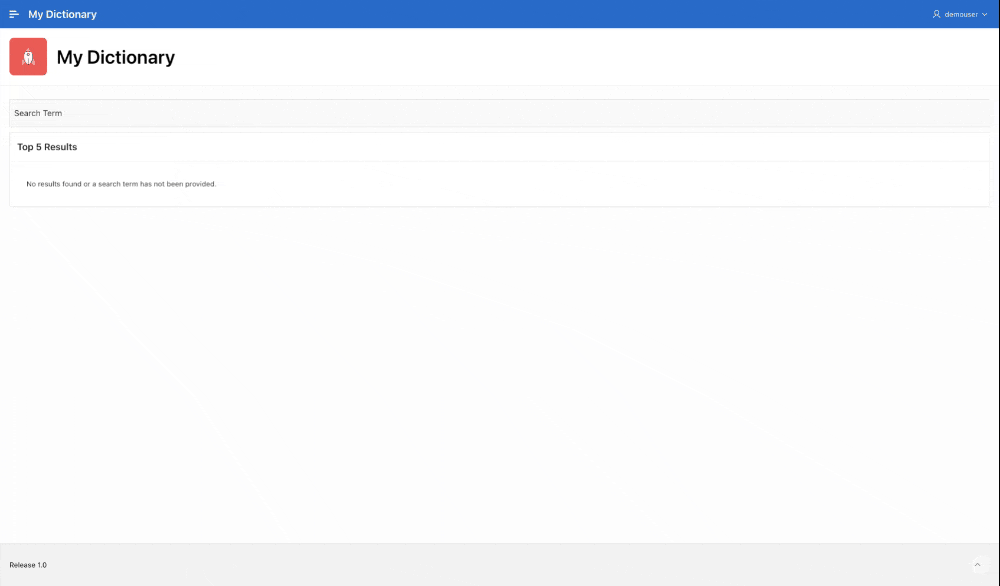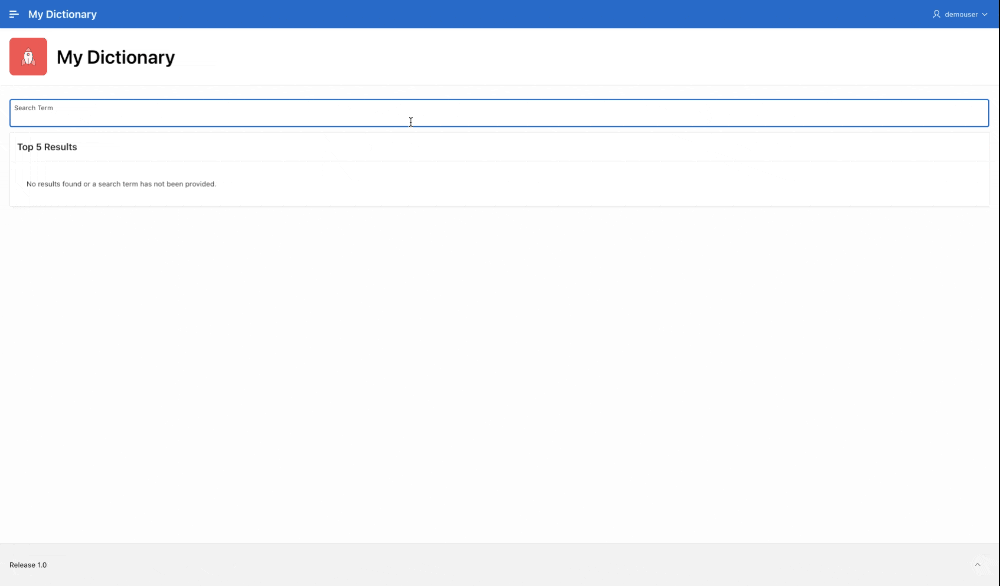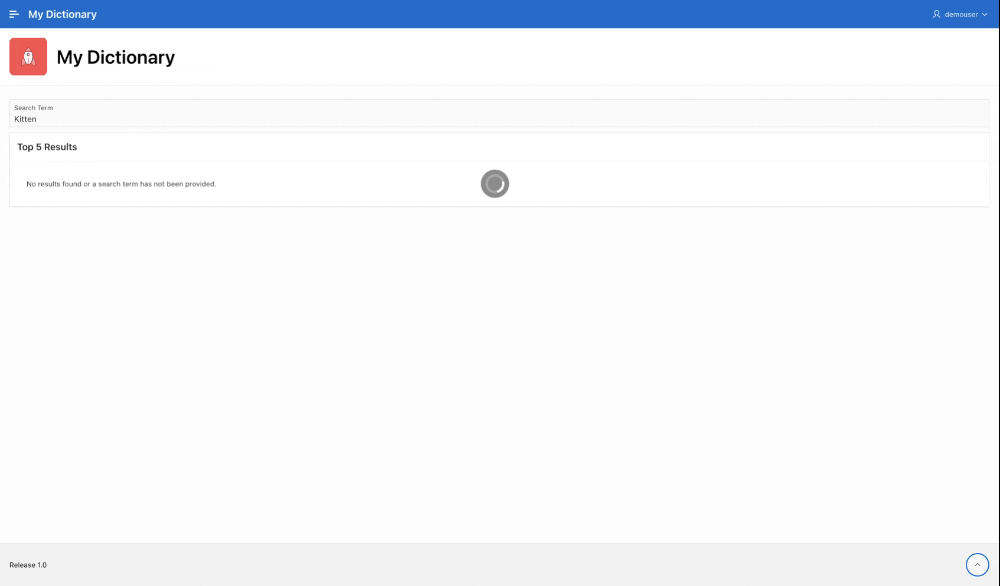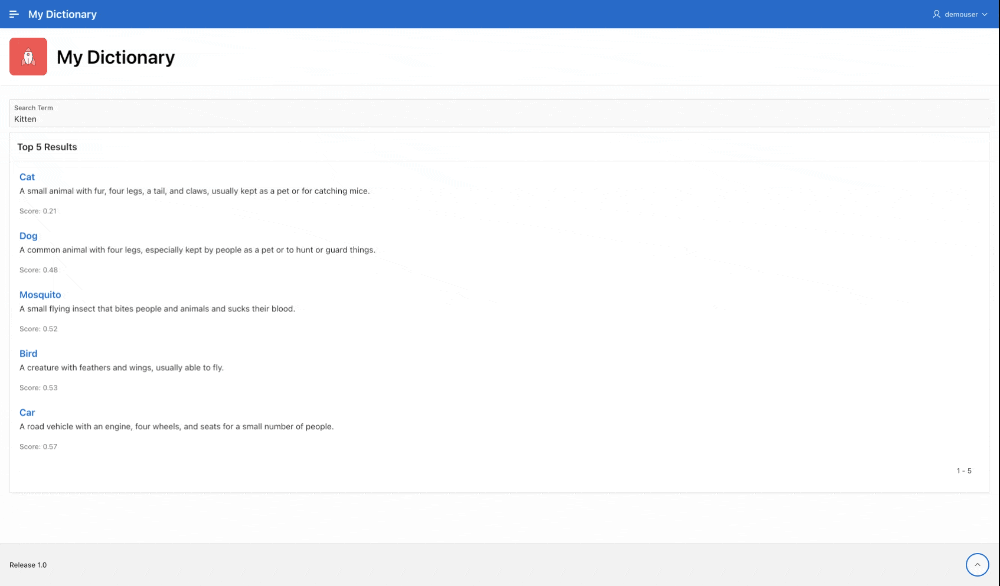
It's not perfect but it at least figured out that a kitten is pretty much a cat. I am not too sure why mosquito is number three though. Maybe it's be cause it can bit people, and sometimes sucks blood when it claws your favourite couch!
Summary
This is only the tip of the iceberg. Next up is text generation but there is currently an issue that prohibits the adding of credentials required to work with third-party REST APIs using the DBMS_VECTOR and DBMS_VECTOR_CHAIN packages on the ADB. Hopefully, this will be fixed very soon.
If this topic interests you and see a potential use case in your organization, please do not hesitate to schedule a call to discuss further.
Credits
- 1 Instructions for installing Conda found here.
- Photo by Christian Lendl on Unsplash
- Special thanks to Louis Moreaux for our quick exchange on the Oracle APEX search functionality.