
It's not unusual for an established principal investigator (PI) to have desks and shelves full of books, journal articles, grant applications, graduate student theses etc. Often, they'd also have a mountain of such material in electronic form and stored on desktop hard drives that sometimes get forgotten. It takes an extremely good memory to remember which articles are relevant to a particular keyword you might be interested in.
Thankfully, there's Oracle Text (and Oracle Application Express (APEX)) to keep you sane!
Setting the Stage
I'm not a researcher myself, so naturally, I don't horde a lot of these materials. For the purpose of this blog post, I will use open data made available, courtesy of the Canadian Government.
The National Sciences and Engineering Council of Canada (NSERC) is one of Canada's federal agencies that is responsible for promoting and providing funding for research in the natural sciences and engineering fields. They publish annual lists of grants that were successfully awarded. You can find them here. I used only one year's (2017) worth of data. There's a lot of research activity going on in the north!
Start off by first creating the necessary data structure to hold the data. I used the Quick SQL tool to quickly generate the necessary DDL script and then create the database.
Quick SQL Shorthand
# settings = { genPK: false, db: 11g }
award
id number /pk
name varchar2(200)
department varchar2(200)
organization_id number
institution varchar2(200)
province varchar2(100)
country varchar2(100)
fiscal_year number
competition_year number
award_amount number
program_id varchar2(50)
program_name varchar2(200)
program_group varchar2(100)
committee_code number
committee_name varchar2(200)
area_of_application_code number
area_of_application_group varchar2(200)
area_of_application varchar2(200)
research_subject_code number
research_subject_group varchar2(200)
research_subject varchar2(200)
application_title varchar2(500)
source varchar2(50)
application_summary varchar2(4000)
Oracle SQL Output
create table award (
id number not null constraint award_id_pk primary key,
name varchar2(200),
department varchar2(200),
organization_id number,
institution varchar2(200),
province varchar2(100),
country varchar2(100),
fiscal_year number,
competition_year number,
award_amount number,
program_id varchar2(50),
program_name varchar2(200),
program_group varchar2(100),
committee_code number,
committee_name varchar2(200),
area_of_application_code number,
area_of_application_group varchar2(200),
area_of_application varchar2(200),
research_subject_code number,
research_subject_group varchar2(200),
research_subject varchar2(200),
application_title varchar2(500),
source varchar2(50),
application_summary varchar2(4000)
)
;
NOTE
Change the DB version as required. The default is 12c, but since I am running the database Express Edition (XE), I used 11g.
Filling Up the Repository
The data from NSERC is fairly clean and formatted. The 2017 data that I downloaded however, was a little too large to import using the built-in SQL Workshop tool in APEX. Fortunately, SQL Developer has a rather sophisticated functionality for doing the same, though it wasn't without challenges. I'll leave data importing methods for another day's discussion. For the purpose of this exercise, I did managed to import at least 5,000 records.
Search-Enabling the Table of Grants Awarded
Oracle Text is a very powerful, no-cost feature of the Oracle Database that doesn't get enough attention as it should. There are many interesting concepts and customizations that can be applied and tune the Oracle Text Index. However, creating a basic index is rather straightforward and should not be feared.
My goal:
- List grant awards that are about fossil fuels and the effects on the environment.
- The corpus contains applications written in both English and French. Users should be able to search with either language.
- Users enter search terms using only one text field, but search must include the following columns:
application_titleapplication_summaryresearch_subjectarea_of_application
Required Database Privileges
To work with Oracle Text, the database user requires a few additional privileges that have already been granted to the role CTXAPP. Assigning the user to the role should be all that's needed:
Create the Oracle Text Index.
begin
begin
ctx_ddl.drop_preference('SEARCH_DATASTORE');
exception
when others then null;
end;
ctx_ddl.create_preference('SEARCH_DATASTORE', 'MULTI_COLUMN_DATASTORE');
ctx_ddl.set_attribute('SEARCH_DATASTORE', 'COLUMNS', 'application_title, application_summary, research_subject, area_of_application');
begin
execute immediate 'drop index award_idx';
exception
when others then null;
end;
execute immediate q'[
create index award_idx on award(application_title)
indextype is ctxsys.context
parameters (q'{
DATASTORE SEARCH_DATASTORE
}')
]';
end;
/
The comments in the procedure shown above explains the basic commands needed to create the index. For convenience, they are listed below:
- Remove any previously created preference with the same name.
- Create the DATASTORE preference.
- Drop any existing index with the same name.
- Create the index.
As mentioned, there are additional indexing elements that could be used to further optimise and customize the search index, but they are out of scope at this time. This simple setup will already allow some powerful search abilities with minimal query design.
Query the Data
There are different operators to use in the WHERE clause, depending on the index type created. In the example, an index of type CONTEXT was created, thus the query will have to be constructed using the CONTAINS operator.
select
id
, application_title
, application_summary
from award
where 1 = 1
and contains(application_title, '"fossil fuels" and environment', 1) > 0
order by search_score desc;
Oracle provides a long list of CONTAINS query operators that allows users to formulate powerful queries. The example above is a simple boolean search (AND operator) requiring both the phrase "fossil fuels" and word "environment" for a match. A simple misspelling of "environment" would likely yield no results. That's where other operators like fuzzy provide a margin error, allowing returning results even when there are no exact matches. The same operator might even forgive simple nuances like "colour" versus "color". There are also wildcard (%) and other operators that are denoted using special characters that could sometimes spell trouble even for a seasoned Oracle Text user.
To protect the untrained user, it is recommended to pre-process the user input and restructure keywords and options into proper query operator constructs. This isn't always easy, and so, we are fortunate that Roger Ford, Oracle Text's Product Manager, posted a blog and useful utility package for parsing user inputs from a simple text field. The syntax closely resembles Google's search operators and should be familiar with most users. The code is available to download at the end of Ford's article.
After compiling the script, functions such as parser.simpleSearch and parser.andSearch will be available to use. Check the comments in the code for details about each function.
SQL> select parser.andsearch('"fossil fuels" environment') from dual;
Querying with APEX
With too little screen space on a blog post, it's easier to demonstrate the search results using APEX. The accompanying demo application showcases Oracle Text integration using two different user interface approaches.
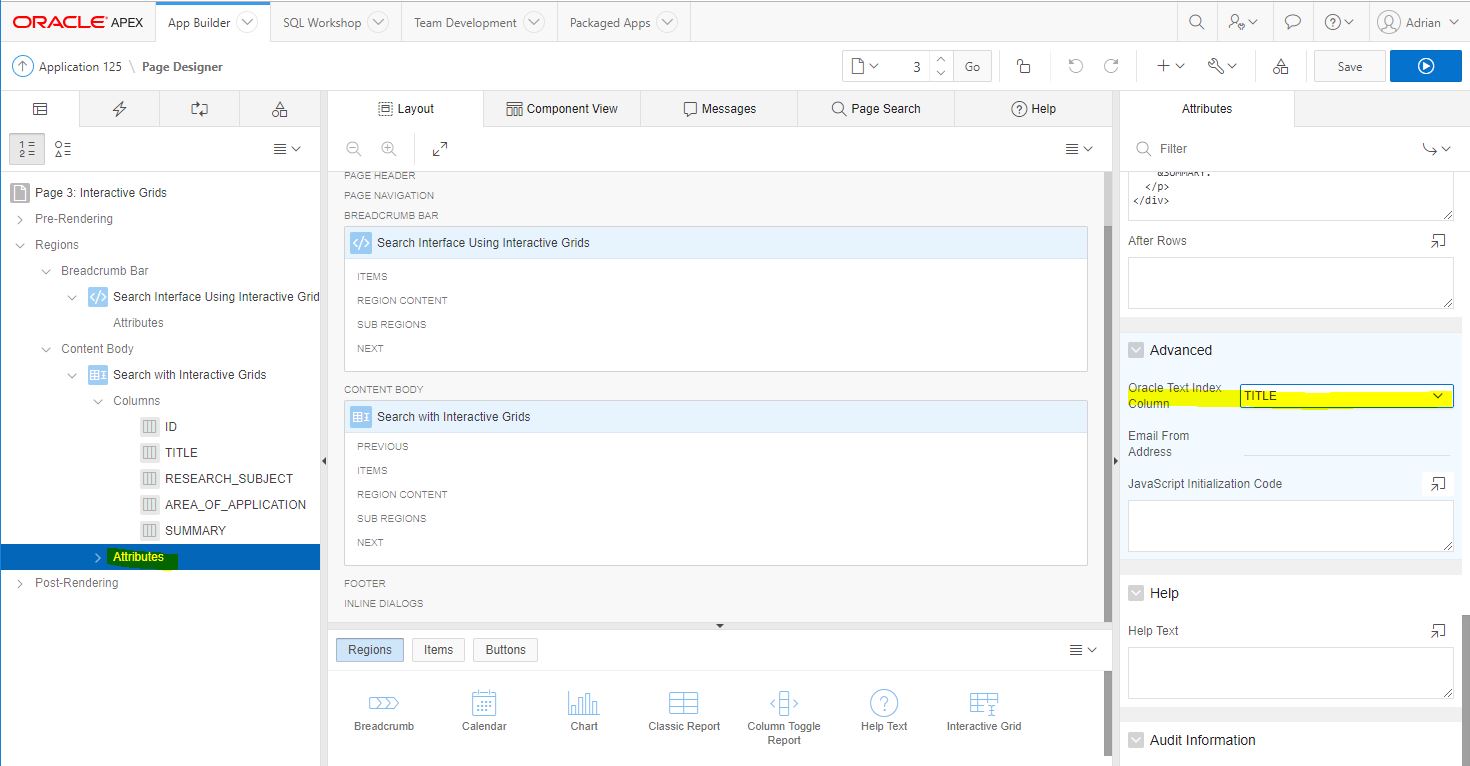
The first uses Interactive Grids (IG) that has built-in support for Oracle Text. After creating the IG, click on Attributes and then on the right, scroll down to the Advanced section and select the indexed column as the Oracle Text Index Column attribute.
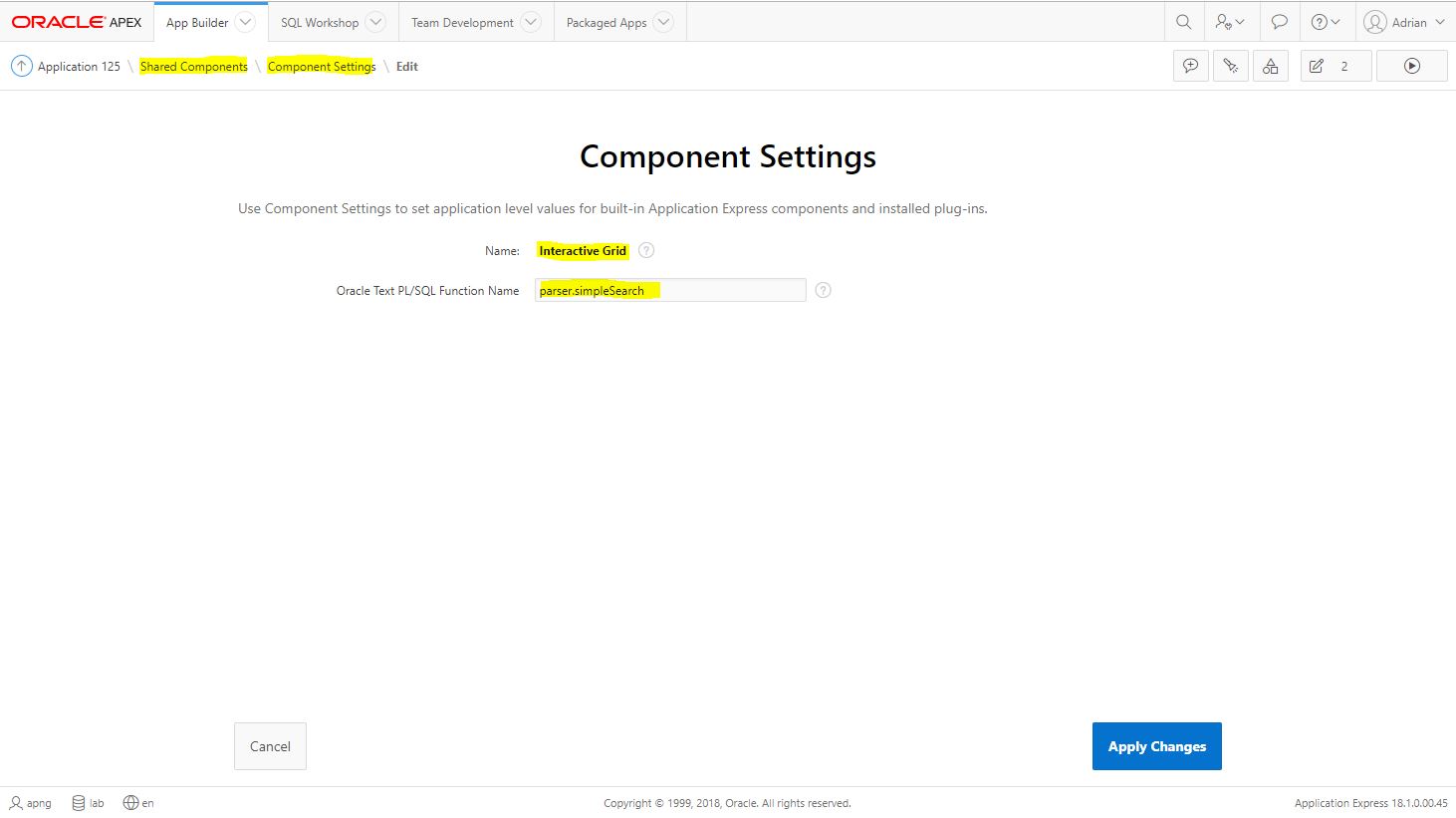
Interactive Grids allows developers to specify a PL/SQL function for converting simple keyword inputs to well-formed Oracle Text syntax. Go to the application's Shared Components> Component Settings > Interactive Grids and then enter the name of the function to use. We can use one of the functions from Ford's Parser package as they meet the requirement of accepting a single string argument.
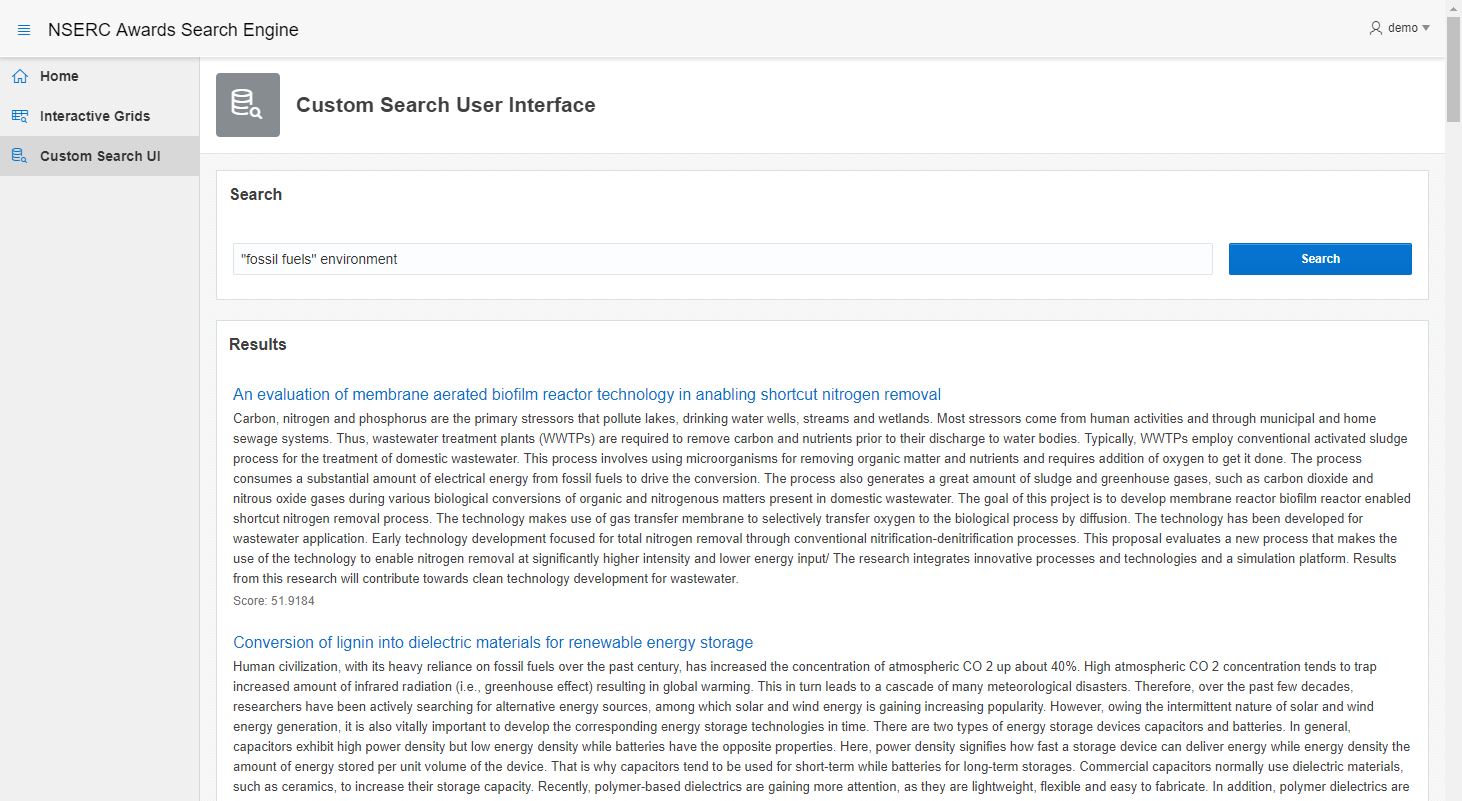
The second approach uses a Classic Report (CR) that allows more flexibility on how the results are displayed, for example, sorting the results by score (descending) and application title (ascending). The user enters the search keywords in a single text field page item (P2_SEARCH_TERMS) that is then parsed and used with a CONTAINS operator to query the table. The SQL query used is as follows:
select
application_title as search_title
, application_summary as search_desc
, round(score(1), 2) as value_01
, 'Score' as label_01
, q'[javascript:apex.message.alert('Not implemented.');void(0);]' as search_link
from award
where 1 = 1
and contains(application_title, parser.progrelax(:P2_SEARCH_TERMS), 1) > 0
Multilingual Search
Both search interfaces will accept either English or French keywords. However, search results are language-specific. If an English keyword is entered, then only applications submitted in English will be returned. Likewise with French search terms. For a heterogenous search, a thesaurus will be required. The parsing function will also need to be "translation-aware", and either accept or transform queries to use operators such as TR. These translation operators will expand the search keywords to include the specified language's equivalent term.
The ctxload utility provides developers the ability to import a thesaurus contained in a plain-text file. Developers can also script the thesaurus:
declare
l_thes_name varchar2(11) := 'SCIENG_THES';
begin
ctx_thes.create_thesaurus(name => l_thes_name);
ctx_thes.create_phrase(tname => l_thes_name, phrase => 'water');
ctx_thes.create_phrase(tname => l_thes_name, phrase => 'waters');
ctx_thes.create_translation(tname => l_thes_name, phrase => 'water', language => 'FRENCH', translation => 'eau');
ctx_thes.create_translation(tname => l_thes_name, phrase => 'waters', language => 'FRENCH', translation => 'eaux');
end;
/
Unfortunately, Ford's parser library does not support translations, but here's an example query that could be used to demonstrate the translation capability. The search term is "water", and the results will return both English and French applications containing either "water" or "eau":
select
id
, score(1) as search_score
, application_title
, application_summary
from award
where 1 = 1
and contains(application_title, 'tr(water, french, scieng_thes)', 1) > 0
order by search_score desc;
Final Notes
Besides searching large bodies of text, Oracle Text has the ability to index and search binary files such as PDF, HTML, XML and even Microsoft Word documents. Check out a full list of supported document formats.
NOTE:
If the document filtering appears not to be working , i.e. a query does not return any expected results, then check that the needed operating system libraries, e.g. compat-libstdc++-33, have been installed. You can test this by running the binary: $ORACLE_HOME/ctx/bin/ctxhx.
Get more background about this thread on the Oracle community forums.
All the technology described and used in this blog post and demo are available to at no cost. That's always a welcomed surprise for any research project.
Software Used
| Software | Cost |
|---|
| Oracle Database 11gR2 XE | FREE |
| Oracle APEX 18.1 | FREE |
| SQL Developer 18.2 | FREE |




